Time series data is ubiquitous in real-world scenarios and crucial for critical applications ranging from energy management to traffic control. Consequently, the ability to reason over time series is a fundamental skill for generalist models to solve complex problems. However, current benchmarks for generalist models largely overlook this dimension.
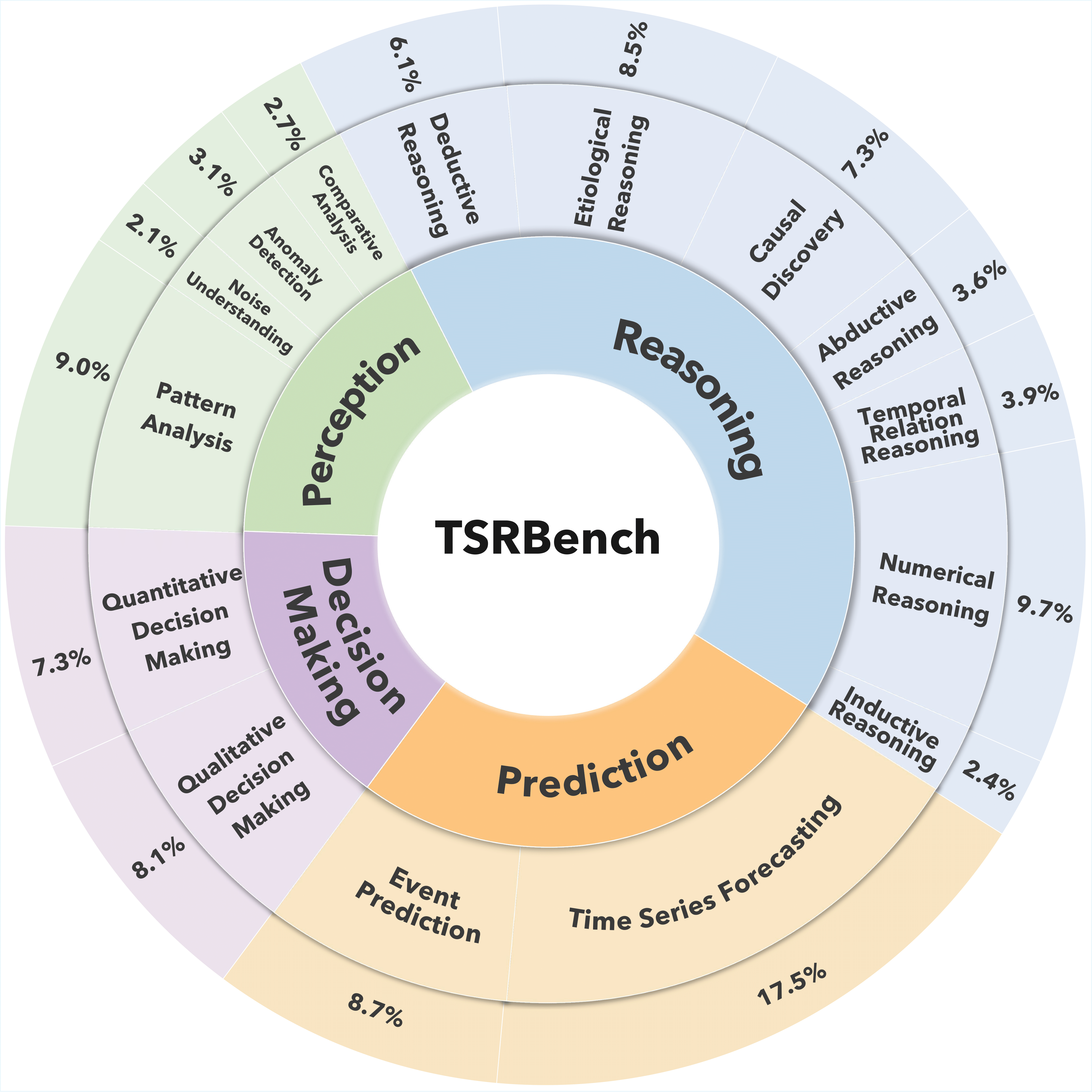
To bridge this gap, we introduce TSRBench, a comprehensive multi-modal benchmark designed to stress-test the full spectrum of time series reasoning capabilities. TSRBench features: (i) a diverse set of 4,125 problems from 14 domains, categorized into 4 major dimensions: Perception, Reasoning, Prediction, and Decision-Making; and (ii) 15 tasks evaluating essential reasoning capabilities (e.g., numerical reasoning, causal discovery, abductive reasoning).
TSRBench provides a standardized evaluation platform that not only highlights existing challenges but also offers valuable insights to advance generalist models.
TSRBench is designed with several key features that set it apart from existing benchmarks: (i) Comprehensive Coverage. TSRBench spans 4 major dimensions with 15 carefully designed tasks covering fundamental to advanced time series reasoning capabilities. (ii) Multi-modal Evaluation. TSRBench supports both textual and visual representations of time series data, enabling evaluation of models' ability to process and fuse information from different modalities. (iii) Diverse Real-world Domains. With data from 13 domains including energy, traffic, finance, and healthcare, TSRBench ensures evaluation on practical, real-world scenarios.
1. Time Series Perception: This dimension evaluates the ability to extract meaningful patterns and insights from time series data, covering four tasks: (i) Pattern Analysis, (ii) Noise Understanding, (iii) Anomaly Detection, and (iv) Similarity Analysis.
2. Time Series Reasoning: This dimension evaluates the ability to derive conclusions from temporal patterns and prior knowledge, covering seven tasks: (i) Etiological Reasoning, (ii) Causal Discovery, (iii) Abductive Reasoning, (iv) Temporal Relation Reasoning, (v) Numerical Reasoning, (vi) Deductive Reasoning, and (vii) Inductive Reasoning.
3. Time Series Prediction: We evaluate predictive capabilities through two tasks: (i) Time Series Forecasting and (ii) Event Prediction.
4. Time Series Decision-Making: This dimension assesses the ability of models to make decisions based on the understanding of both time series and context. We evaluate this through two aspects: (i) Qualitative Decision-Making and (ii) Quantitative Decision-Making.
Model performance on TSRBench across 15 tasks in 4 dimensions. For proprietary models, "(T)" denotes textual time series, "(V)" denotes visualized time series, and "(T+V)" denotes both modalities.
Through extensive experiments evaluating over 30 leading proprietary and open-source LLMs, VLMs, and TSLLMs, we uncovered several key findings:
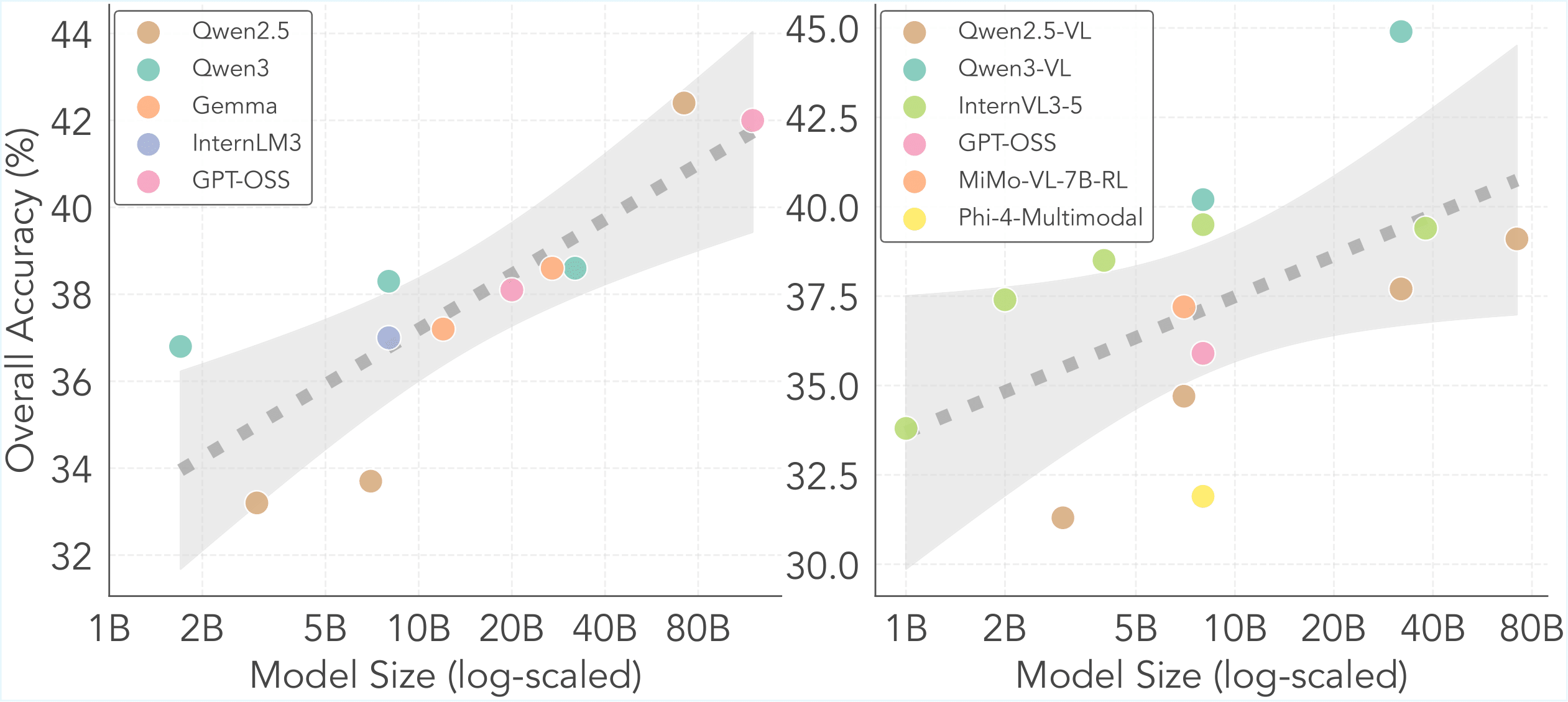
Finding 1. The scaling law still holds for most of the time series reasoning tasks on both LLMs and VLMs, except for time series prediction.
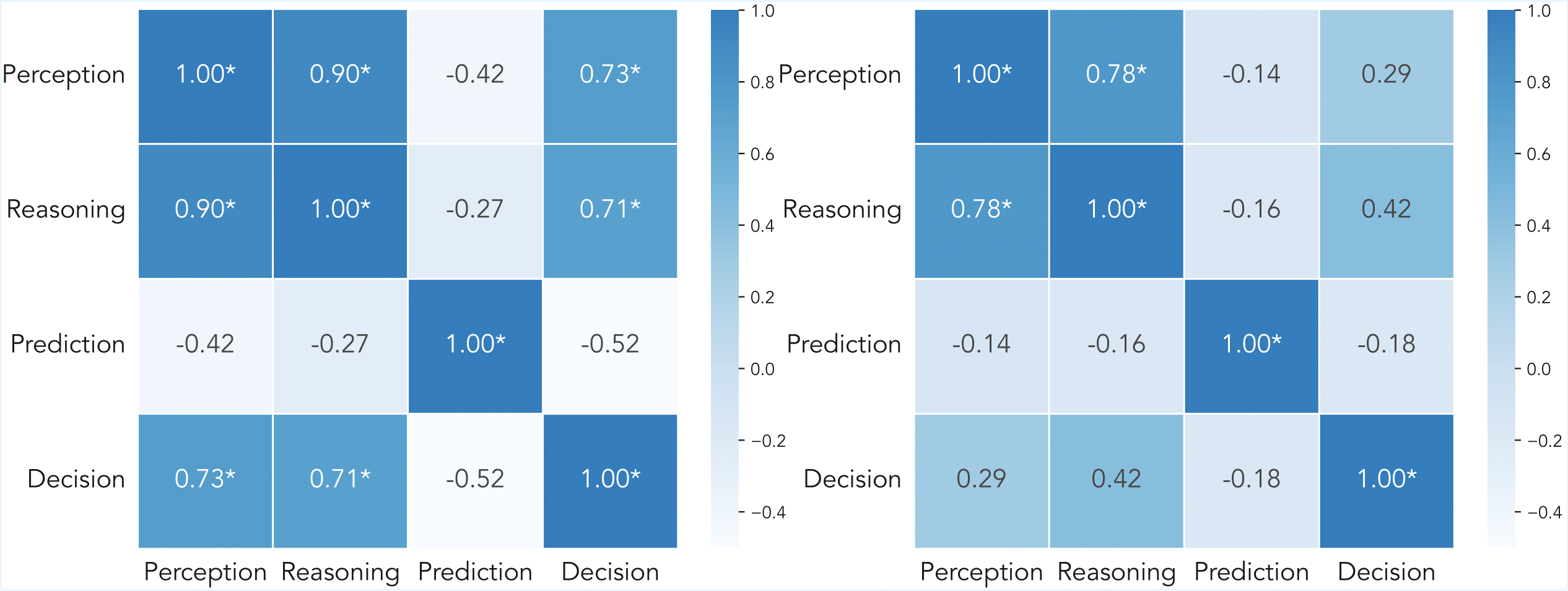
Finding 2. Perception, Reasoning, and Decision tasks are highly correlated, and have weak correlation with the Prediction task.
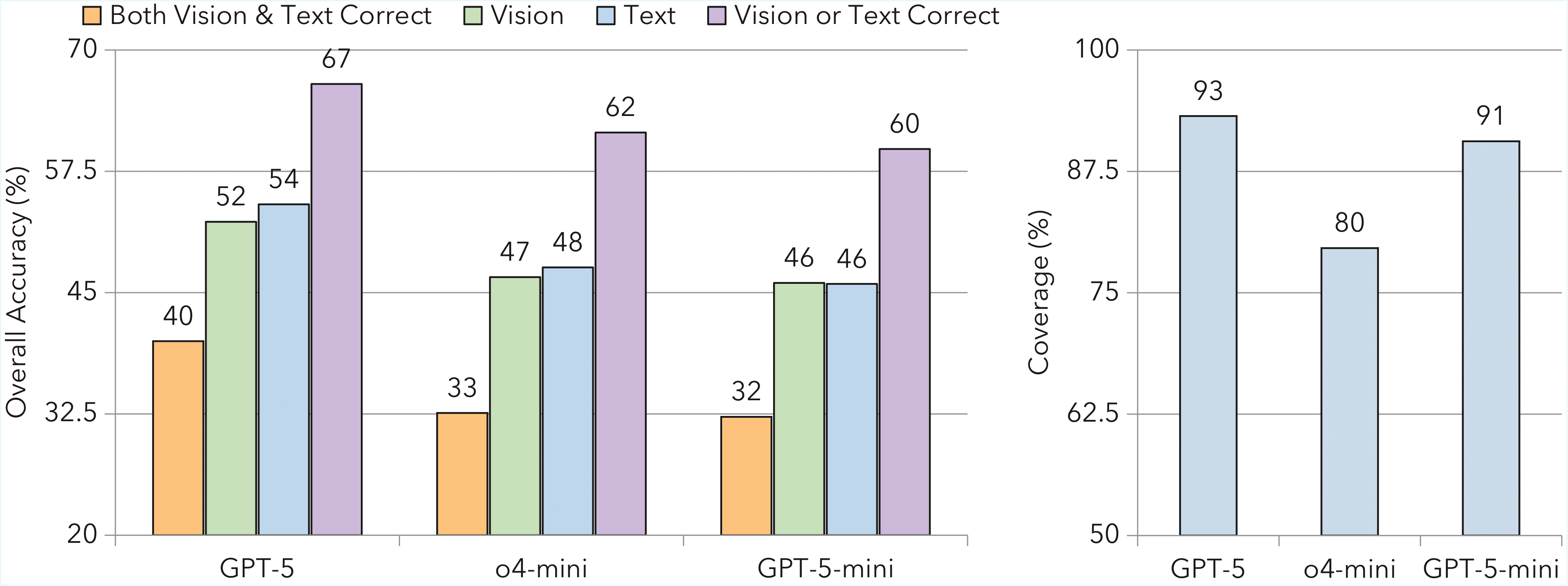
Finding 3. Although the textual and visual representations of time series achieve similar performance, they are strongly complementary.
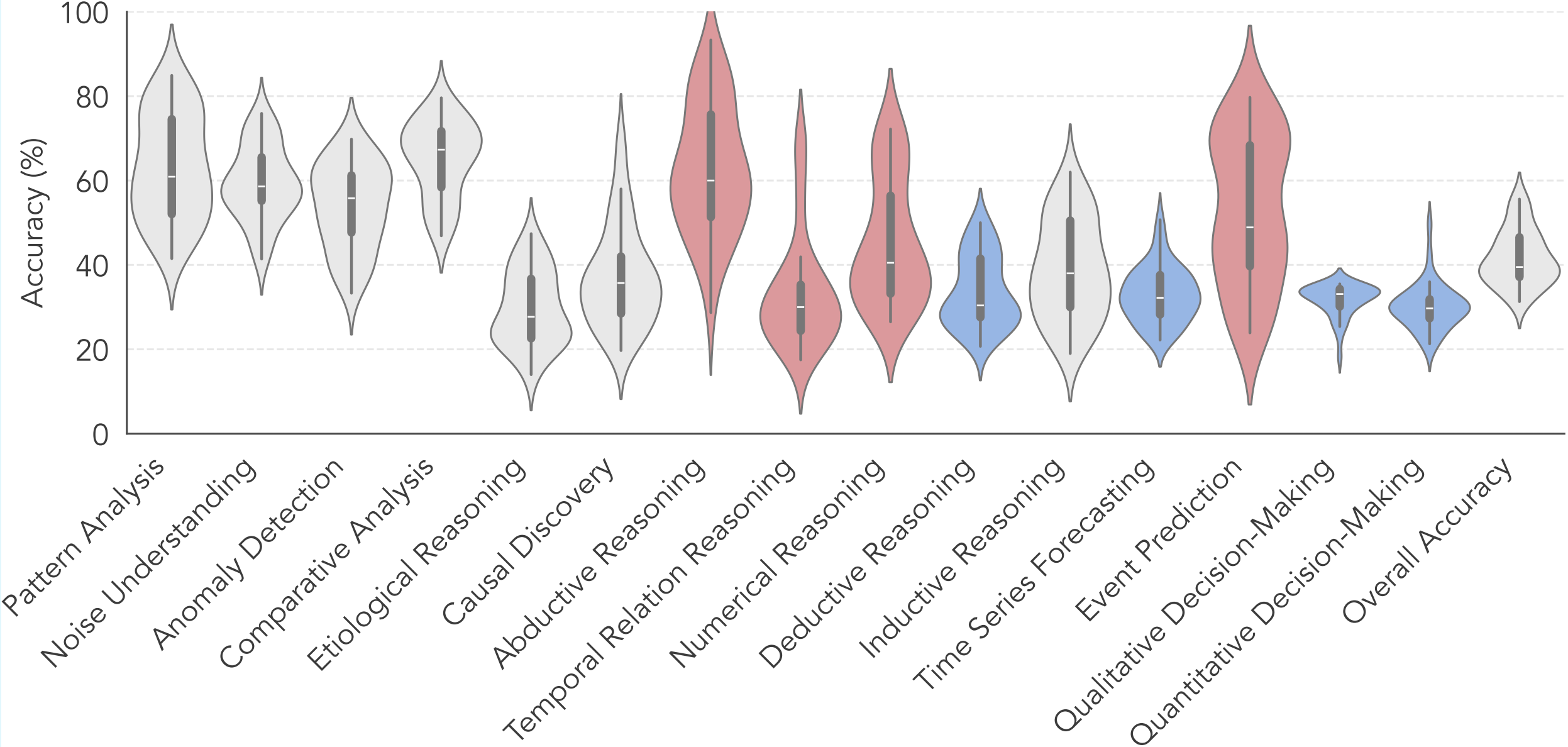
Finding 4. Tasks with high variance, highlighted in red in Figure 6, indicate that poorer-performing models can be improved through distillation from stronger ones, while low-accuracy, low-variance tasks shown in blue reveal shared weaknesses requiring better training data.
Use arrow keys (← →) or buttons to navigate through cases
@article{yu2026tsrbench,
title={TSRBench: A Comprehensive Multi-task Multi-modal Time Series Reasoning Benchmark for Generalist Models},
author={Yu, Fangxu and Guo, Xingang and Yuan, Lingzhi and Kang, Haoqiang and Zhao, Hongyu and Qin, Lianhui and Huang, Furong and Hu, Bin and Zhou, Tianyi},
journal={arXiv preprint arXiv:2601.18744},
year={2026}
}


